This post is part of the “Learning Flash: For Storage Engineers” series. Click here, if you missed the intro post.
For us storage engineers, more has almost always been the answer to storage performance problems. For any given performance complaint, it is often solved by adding more cache, more ports, more controllers and, especially, more disk. However, it is important to understand that more doesn’t solve the problem of slow; it solves the problem of congestion. These are two different, but related problems and it is important to understand the difference.
Grocery Store IOPs:
Let’s say you manage a grocery store and part of your duties is to ensure speedy checkout for customers. As the checkout manager, you monitor efficiency of the checkout lanes and ensure there are enough open lanes for customers to not have to wait. You have recently started to receive customer complaints that it takes too long to checkout, and in response, you double the throughput of your lanes by adding twice the clerks. You are pleased to see from your office window that now there are always 3-4 open lanes. Yet, inexplicably, you continue to receive complaints about long checkout times. If there are always open lanes, how could the experience possibly be slow?
For a customer, the checkout experience is based on 2 different wait metrics; the time in line and the time actually being checked-out. If we only monitor the utilization of lanes, we miss an important metric in measuring the overall efficiency of the checkout lanes. In this example, all the checkout clerks were using pen, paper and calculators to total bills. The checkout process was taking 10 minutes even with no queue! As the manager, you didn’t need to add more lanes, you needed to make each lane faster.
If, instead, you would have upgraded the clerks to modern computerized checkout systems, the checkout time could have dropped from 10 minutes to less than 1 minute. An interesting benefit of this efficiency increase would be a reduction in the required lanes. In effect, one modern checkout lane could now provide the same throughput as 10 of the manual lanes.
In the above example, you solved for congestion initially by adding more lanes. However, the problem was speed, not congestion. Not until you made the individual lanes faster did the customer complaints stop.
Flying to Australia
Just to hammer this point home, let’s say you want to fly from KC to Australia. The airline clerk informs you that the flight is 18 hours long. After complaining about the flight time and speaking with a manager, the airline says they will resolve the issue by sending 2 planes instead of 1. This is obviously absurd because a second plane will do nothing to shorten the 18 hour flight. It would only help if the flight was over-booked. In this case, the airline needs faster planes, not more of the same.
Latency vs IOPs
Managing a storage system is very similar to the above scenarios. As storage engineers, we almost solely focus on drive utilization and aggregate IOPs. The only time we typically look at latency (time taken for I/Os to complete), is when we are troubleshooting congestion. If congestion is found, we can improve latency by eliminating congestion (adding drives). If congestion is not the problem, we are stuck. We can’t make disk drives faster.
Let’s review the basic terms of measuring storage performance:
Latency: A measure of time. Usually time for an individual I/O to complete. Reducing latency improves responsiveness to all applications and increases total throughout and bandwidth. Latency affects everything.
1 Second / I/Os = Avg. Latency
1000ms / 180 I/Os = 5.56ms Avg Latency
Throughput (IOPS): A measure of quantity. Number of I/O transactions that can complete in a second. Influenced by latency and number of workers (drives) servicing I/O. Improving IOPS potential enables more parallel applications to run concurrently, but may not improve individual application performance.
(Second / Avg. Latency) x Number of Workers (drives) = IOPS
(1000ms / 5.56ms) x 10 Drives = 1800 IOP/s (not factoring in RAID and other overhead)
Bandwidth: A measure of payload: Amount of data that can be transferred over a given time (usually a second). Direct relationship with IOPs and I/O size. Improving bandwidth potential enables more data to be streamed in a shorter period of time.
IOPS * Block Size = (K/M)B/s
100 IOPS * 512Kb Block Size = 50MB/s
It is critical to understand the difference between serial and parallel I/O types when engineering and troubleshooting application performance. Serial I/Os have to occur in sequence; meaning that a previous transaction must be confirmed (acknowledged) as complete before subsequent transactions can be issued. Nearly all applications require some or much of their transactions to be in order. Consequently, parallel I/Os don’t have those constraints and can occur regardless of order. Portions of applications with multiple, independent threads can process parallel I/O, and groups of independent applications sharing the same storage system all process I/O in parallel—at least in relation to each other.
This is where IOPS vs latency matters. Only applications or portions of applications that don’t require serial I/O will see benefits from adding drives, and, they will only see benefits if congestion was a problem. Applications that are sensitive to individual transaction completion times (latency sensitive) won’t see any benefit to adding more drives, unless latency was high as a result of congestion.
However, improving the speed at which every transaction can complete by reducing latency will improve performance across the board. Just like the customers in the upgraded checkout lanes, individual transactions can be completed much faster which also enables more transactions to be completed per second which improves overall throughput as well. A reduction in latency provides a wholistic improvement in performance—whereas improving IOPS through drive count only reduces congestion.
The Storage Impact:
Unfortunately, as storage engineers, we often have no visibility into when applications are latency dependent. DBAs routinely complain about long-running jobs and high disk wait times, yet our storage resources show well within normal utilization. From our perspective, the storage can sustain more IOPS so it must be an application or database problem. We believe that if the application were properly architected, it should be able to utilize all of the available parallel resources. This is a common misconception. Some applications require serial I/O and there is nothing that can be done to safely change that. These applications require low latencies.
Let’s look at a few scenarios. In order to reduce complexity, let’s assume no RAID overhead or caching is at play—only RAW disk IOPS. Sure caching helps, but if caching was the fix-all, you could run your applications on tape.
In the first example, you can see an average disk latency of 8ms and underutilized drives. The maximum IOPS per drive with an 8ms latency is about 125 with an aggregate max IOPS of 1,000 (if the drives were 100% utilized). In this scenario, the DBA complains about performance and high disk waits.
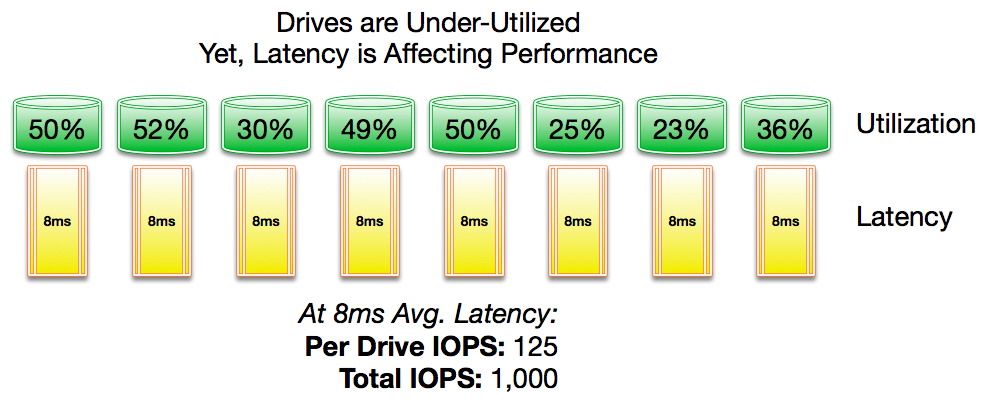
A storage engineer would argue with the idea of a storage “problem” because drive utilization is relatively low, but may finally cave and agree to install additional drives. If the drive count were doubled, the maximum IOPS would double, and the drive utilization would be further reduced.
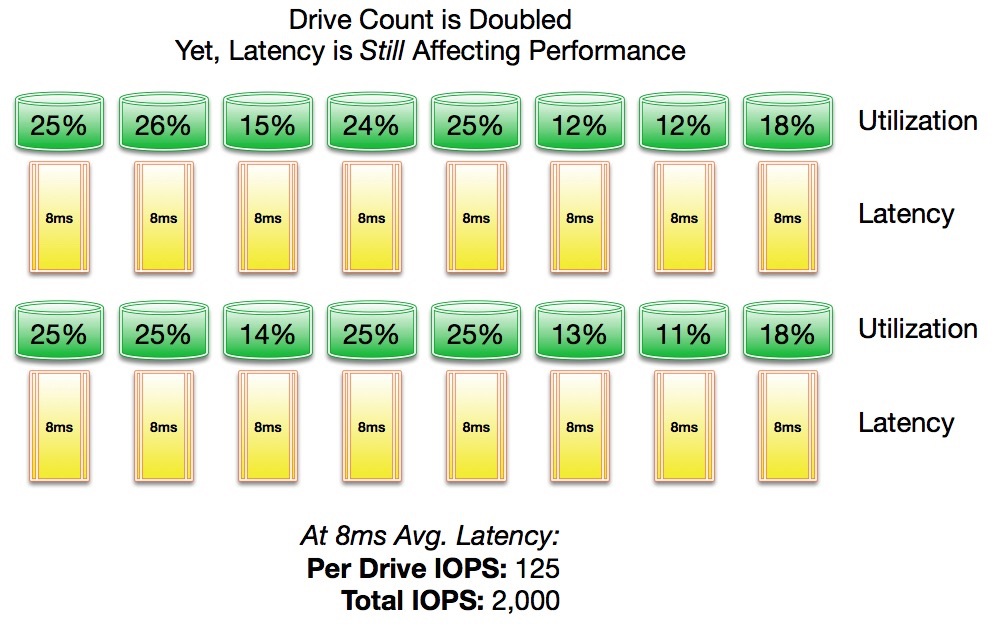
Problem solved? No. In this scenario, the wait is driven by latency, not congestion. This application is serial in nature, so it is waiting for each transaction to be processed before sending subsequent transactions. It is effectively limited to the IOPS of a single drive as each drive must complete the current transaction before a new transaction can be issued. In this case, the database would see little, if any, improvement with more drives.
As an alternative scenario, what if the drive count remained the same, but we changed another factor. Let’s swap the mechanical drives for solid-state drives, thereby dropping the latency from an average of 8ms to an average of .5ms. This means each drive will be able to process individual transactions 16 times faster. With the per-transaction latency reduction, even an application with serial I/O will see a major performance improvement.

As a healthy side-effect, IOPS per drive increase to 2,000 and max IOPS increase to 16,000. Since congestion is far from being a problem, you could even cut the drive count in half and the application would still benefit from the same transaction time improvements.
The Bottom Line: Latency Matters
Storage systems are responsible for storing and retrieving nearly 100% of enterprise data, but they are still mechanical devices. No other piece of IT infrastructure relies on mechanical components in the I/O path—the rest of the infrastructure is 100% silicon!
If you are looking at drive utilization to determine if you “need” solid-state, you are looking in the wrong place. Look at your average latency metrics. Every ms over 1ms is a factor by which you could accelerate how your business processes information and dramatically improve the experience of your users and customers.
You have never been closer to being a storage hero.
In my next post, I’ll discuss the differences between magnetic and electric storage and how transistors form the foundation of flash memory technology.
 Dale Carnegie: How To Win Friends and Influence People
Dale Carnegie: How To Win Friends and Influence People Dave Ramsey: The Total Money Makeover: A Proven Plan for Financial Fitness
Dave Ramsey: The Total Money Makeover: A Proven Plan for Financial Fitness